JSP에서 정신없이 DB로 아니 벌써 넘어왔다고?? 싶은 한 주였습니다 새로운 정보들이 넘치듯 들어오고 있어서 스스로가 잘하고 있는 건지... 이게 맞나?? 싶은 한 주였습니다 하지만 힘내서 달려가야죠 할 수 있는 건 그것뿐!!!!
관계형 (RDBMS)
Oracle
DB2 -금융권에서 많이 사용됨
MYSQL
MariaDB
PostgreSQL
ETC (NOSQL)-빅데이터 딥러닝 쪽 분야
흔히 DB라고 부르지만 사실은 우리가 사용하는것은 DB인스턴스 (XE)
면접 마지막 질문팁 : 개발도구는 어떤 걸 쓰는지 , 개발인원은 몇 명인지
SQL은 Structured Query Language (구조화된 질의 언어)의 줄임말로
관계형 데이터베이스 시스템(RDBMS)에서 자료를 관리 및 처리하기 위해 설계된 언어입니다
<현재 사용하는 DataGrip =데이터 편집기>

SQL 문법의 종류
DDL(Data Definition Language) 데이터 정의 언어
각 릴레이션 <오브젝트>을 정의하기 위해 사용하는 언어 (CREATE) (DB설계 단계에서 보통 하는 일)
⭐DML(Data Manipulation Language) 데이터 조작 언어
데이터를 추가 , 수정 , 삭제하기 위한 즉 데이터 관리를 위한 언어 (INSERT, UPDATE, Delete) (INSERT,UPDATE,Delete 숫자로 반환됨)
Query → (SELECT)(조회)
(SELECT)(조회)하면 DB 쿼리 분석을 하고 분석 결과로 실행계획을 세움
(실질적으로 개발단계에서 하는 일)
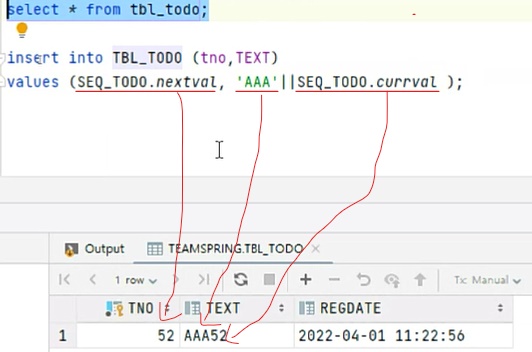
INSERT 사용법
insert into 대상 ( 구조 )
values( 구조 )——-직접적으로 넣어주는 방법
(select......... from.....) 집합으로 한꺼번에 데이터를 밀어 넣을 때
ex) (select SEQ_TODO.nextval, 'AAA'||SEQ_TODO.currval from TBL_TODO);Delete 사용법
delete from 대상
UpDate 사용법
update from 대상
set 칼럼=값 <칼럼을 값으로 바꿀 거다>
where 조건절
Select 사용법
select___가공_______ → 가공을 하기 싫으면 “ * ”을 사용해서 순수한 데이터가 그대로 나온다
form __대상 집합__
where 절 - 자료에 조건을 부여해서 제한을 줄 수 있음
order by - 그룹 처리 <도출된 결과를 정렬>
ex) select *from tbl_todo order by tno desc;union - 합집합
DCL(Data Control Language) 데이터 제어 언어
사용자 관리 및 사용자별로 릴레이션 또는 데이터 관리하고 접근하는 권한을 다루기 위한 언어
테이블
테이블 <정렬된 데이터 집합(값)의 모임>
네이버 카페를 만든다고 가정했을 때 카페마다 테이블이 필요할까? 아니면 하나의 테이블에 모든 카페의 정보를 넣어야 할까?
DB는 입출력의 횟수가 적을수록 데이터를 찾는 게 빨라진다 그런 게 테이블을 전부 따로 만든다면 DB가 정보를 찾을 때 모든 테이블을 확인해야 한다 그래서 테이블 하나에 정보를 넣는 방법을 보통 사용한다
ORM이란
Object Relational Mapping, 객체-관계 매핑
객체와 관계형 데이터베이스의 데이터를 자동으로 매핑(연결)해주는 것을 말한다. 객체 지향 프로그래밍은 클래스를 사용하고, 관계형 데이터베이스는 테이블을 사용한다. 객체 모델과 관계형 모델 간에 불일치가 존재한다. ORM을 통해 객체 간의 관계를 바탕으로 SQL을 자동으로 생성하여 불일치를 해결한다. 데이터베이스 데이터 <—매핑—> Object 필드 객체를 통해 간접적으로 데이터베이스 데이터를 다룬다.
출처: https://gmlwjd9405.github.io/2019/02/01/orm.html
Table Space
Table들이 모이면 Table들을 묶어주는 공간을 Table Space라고 한다
테이블에는 도메인(레코드, 로우, 튜플, 개체 )을 보관하고 도메인은 식별자(PK Primary Key)를 가지고 있다
식별자를 만드는 방식
직접 지정 - ex) 회원가입 <pk가 유니크해야 함>
자동 지정 - ex) 게시판 (중복만 없으면 됨)
자동 지정을 할 때 사용하는 대표적인 것에는 시퀀스( Sequence)와 Auto Increment 가 있다
시퀀스( Sequence)는 자동으로 만들어지는 번호를 만들 때 사용하는데 오라클에서 시퀀스( Sequence)를 사용할 때는 nextval과 currval 만 기억하자
nextval는 현재 시퀀스의 다음 값을 불러온다.
currval는 현재 시퀀스가 몇 번째에 있는지 알려주는 명령어다.
Sequence 연결할 때 nextval 먼저 해줘!!
nextval 없이 바로 currval을 하게 되면 이러한 에러가 뜬다 공간을 만든 적이 없기 때문에 찾을 수도 없다 그러니 항상 먼저 nextval을 먼저 해주자

대부분의 DB는다 같은 공간을 사용하는 것 같지만 사실은 작업을 할 때 각자 공간이 생기고 각자의 공간에서 작업을 하고 Commit를 하면 실제 DB에 저장이 된다
직접 지정을 이야기하며 DB의 Delete
실제로 DB에서 Delete 작업은 거의 없다 왜냐하면 Delete작업을 하면 그 데이터와 관련된 모든 데이터를 지워야 하기 때문에 그 과정에서 DB안에서 많은 것이 틀어질 수 있기 때문에
테이블에 정보 입력해보기
데이터를 집합 단위로 처리해서 더미 데이터 만들어보기 <from>
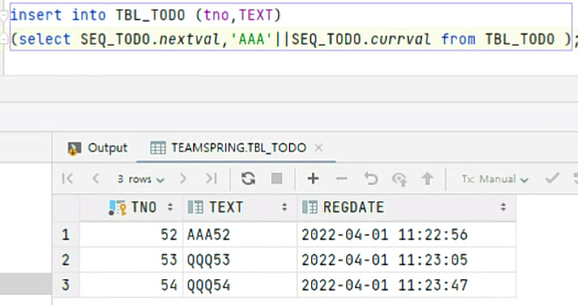
from은 뒤에 나오는 TBL_TODO의 집합 전체를 가져와서 값을 넣어준다
현재 3개의 데에터가있는데 from을 하면 3개의 데이터가 더 들어가 6개가 되고 한 번 더 실행하면 6개의 데이터 집합이 추가돼서 12개 그다음은 24개 이런 식으로 너무나 간단하게 중복이 없는 더미 데이터를 만들 수 있다

count를 사용하면 현재 DB의 데이터가 얼마나 있는지 확인할 수 있다
정규화 (normalization): 어떻게 하면 데이터를 효과적으로 보관할 수 있을까?
데이터를 중복으로 저장하면 일관되지 않은 데이터, 비정상적인 삽입 갱신 삭제 처리, 디스크 공간 낭비 등 많은 문제를 일으킨다. 정규화는 중복 데이터를 저장하면서 일으키는 문제점을 없애려고 정보를 주제별로 분할하는 프로그램을 의미한다.
기본 목표는 테이블 간에 중복된 데이터를 허용하지 않는다는 것
테이블을 만드는 요령
TODO테이블 설계해보기

테이블을 만들 때 가장 중요한 것
pk - 성능에 영향을 줌 , 식별 < 논리적인 의미와 물리적인 의미 둘다를 가지고 있음 >
시간 - 생성되는 시간을 기록 , 변경에 대한 시간
삭제 플래그 - 삭제 여부
작업한 사람
NotNull - 테이블을 만들 때 칼럼을 정의하는데 그때 Not Null 제약조건을 명시하게 되면 그 해당 칼럼에는 반드시 데이터를 입력해야만 한다.
<pk 잡으면 자동으로 index가 잡히는데 null 있으면 index가 생성이 안된다 그래서 나중에 DB에 성능 향상 튜닝을 하기 위해서는 NotNull을 해야 한다 , 검색을 하거나 정렬을 해야 하는 부분은 NotNull을 한다고 생각하자>
DB입장에서 Null 이 많다는 건 쓸모없는 공간이 많아진다는 뜻이다
오라클 데이터 타입
문자열
- VARCHAR2(사이즈) — 가변 길이 문자 / 최대 4000BYTE / 디폴트 값은 1byte
- CHAR(사이즈) ——고정길이 문자 / 최대 2000byte / 디폴트 값은 1byte → Y&N <boolean>에 쓰임
숫자
- NUMBER → 소수점
- INT
시간 <DB는 시간을 중요하게 생각함>
- DATE - BC 4712년 1월 1일부터 9999년 12월 31일, 연, 월, 일, 시, 분, 초까지 입력 가능
- TIMESTAMP -연도, 월, 일, 시, 분, 초 + 밀리초까지 입력 가능
'개발자 성장 일지' 카테고리의 다른 글
| 2022.04.05 인덱스 그리고 DB 설계 (0) | 2022.04.05 |
|---|---|
| 2022.04.04 DB 와 WEB 연결 (0) | 2022.04.05 |
| 2022.03.31 죽어라 DB야 (0) | 2022.03.31 |
| 2022.03.29 수업일지 (0) | 2022.03.29 |
| 2022.03.28 Servlet 그리고 모델 1 , 모델 2 (0) | 2022.03.28 |